Автоматизація рахунків: як перетворити PDF і фото в дані Google Sheets
Рахунки, акти й квитанції рідко приходять у зручному форматі. Один постачальник надсилає PDF на пошту, другий кидає фото в Telegram, третій прикріплює скан до заявки. А в кінці хтось усе одно вручну переносить дату, суму, валюту й контрагента в Google Sheets. Саме з цього місця починається практична автоматизація рахунків: не з великої ERP, а з нормального процесу "файл -> дані -> перевірка -> таблиця".

Головна помилка в таких задачах - намагатися одразу зробити "повністю автоматичну бухгалтерію". Це майже завжди поганий старт. OCR може неправильно прочитати цифру, модель може не впізнати валюту, а постачальник може прислати документ у новому шаблоні. Тому правильна ціль на першому етапі інша: прибрати ручне копіювання, але залишити контроль там, де є ризик помилки.
Якщо у вас уже є процеси на Google Sheets, Apps Script або невеликі Node.js-сервіси, така автоматизація добре лягає в існуючу архітектуру. Вона схожа на сценарії з автоматизацією звітності в Google Sheets, але замість готових табличних даних ми спочатку витягуємо структуру з неструктурованого документа.
Де бізнес втрачає час на рахунках
Ручне внесення рахунків виглядає дрібницею, поки таких документів 5-10 на місяць. Але коли їх стає 30, 50 або 100, проблема росте не лінійно. Людина не просто копіює дані. Вона відкриває файл, шукає потрібні поля, перевіряє валюту, думає, чи це новий документ або дубль, і тільки потім записує рядок.
Типові точки помилок:
- сума перенесена без ПДВ або навпаки з ПДВ;
- дата документа переплутана з датою оплати;
- валюта не вказана або прочитана неправильно;
- один і той самий рахунок внесений двічі;
- посилання на файл не збережене, і потім складно перевірити джерело;
- документ лежить у чаті, а таблиця живе окремо.
Автоматизація рахунків має закрити саме ці місця. Не "зробити красиво", а зробити так, щоб кожен документ мав джерело, статус, набір витягнутих полів і зрозумілий маршрут перевірки.
Архітектура: файл, OCR, JSON, валідація, Sheets
Мінімальний робочий процес можна зібрати з п'яти частин.
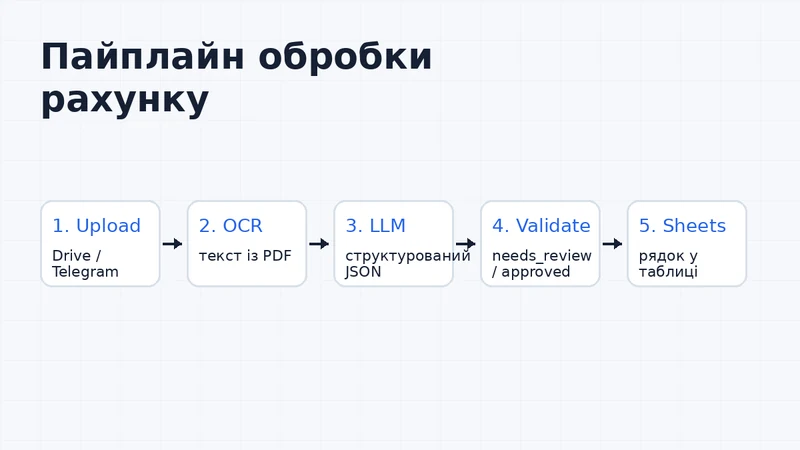
- Джерело файлу. Це може бути папка в Google Drive, вкладення з Gmail, файл із Telegram або ручне завантаження в адмінку.
- OCR-шар. Він перетворює PDF або фото в текст.
- LLM-шар. Модель бере текст і повертає структурований JSON.
- Валідація. Скрипт перевіряє, чи є дата, сума, валюта, номер документа, контрагент.
- Google Sheets. Таблиця отримує рядок зі статусом, полями й посиланням на оригінальний файл.
Це не обов'язково має бути складна система. Для першої версії достатньо Google Drive, Apps Script або невеликого Node.js-сервісу, OpenAI API і таблиці. Якщо обсяг виросте, той самий принцип можна перенести в чергу, базу даних або окремий бекенд.
Які поля варто витягувати
Перед кодом треба домовитися про структуру. Якщо її немає, автоматизація швидко перетворюється на набір винятків.
Для старту достатньо такої таблиці:
| Поле | Навіщо потрібно |
|---|---|
date | дата рахунку або документа |
vendor | постачальник або контрагент |
invoice_number | номер рахунку, якщо він є |
amount | сума |
currency | валюта |
category | тип витрати або напрям |
status | new, parsed, needs_review, approved, error |
sourcefileurl | посилання на оригінальний файл |
Важливо не пропускати sourcefileurl. Без нього таблиця втрачає зв'язок із реальним документом. Коли через місяць треба перевірити суму, ви не маєте шукати файл по пошті або чатах.
Prompt для витягування JSON
Модель не повинна "писати відповідь". Її задача - повернути структуру. Це ближче до мікросервісу, ніж до чату.

Приклад системного промпта:
const systemPrompt = `
Ти витягуєш дані з рахунків, актів і квитанцій.
Поверни тільки JSON без пояснень.
Формат:
{
"date": "YYYY-MM-DD або null",
"vendor": "string або null",
"invoice_number": "string або null",
"amount": number або null,
"currency": "UAH/EUR/USD або null",
"category": "string або null",
"confidence": number від 0 до 1
}
Правила:
- не вигадуй значення, якщо їх немає в тексті;
- якщо сума нечітка, amount = null;
- якщо не впевнений у полі, зменш confidence;
- не додавай текст поза JSON.
`;Тут ключове слово - "не вигадуй". Для рахунків краще отримати null і статус needs_review, ніж красивий, але неправильний рядок.
Валідація перед записом у таблицю
OCR і LLM - це не фінальна істина. Перед записом у таблицю треба перевірити дані звичайним кодом.
function validateInvoiceData(data) {
const errors = [];
if (!data.vendor) errors.push("vendor_missing");
if (!data.date || !/^\\d{4}-\\d{2}-\\d{2}$/.test(data.date)) {
errors.push("date_invalid");
}
if (typeof data.amount !== "number" || data.amount <= 0) {
errors.push("amount_invalid");
}
if (!["UAH", "EUR", "USD"].includes(data.currency)) {
errors.push("currency_invalid");
}
const status = errors.length ? "needs_review" : "parsed";
return {
...data,
status,
errors,
};
}Це простий приклад, але він уже змінює якість процесу. Таблиця отримує не просто "що розпізнав ШІ", а контрольований результат із поясненням, чому документ треба перевірити.
Статуси захищають процес від тихих помилок
Автоматизація рахунків без статусів небезпечна. Вона може виглядати успішною, навіть коли частина документів не обробилася або потребує ручної перевірки.
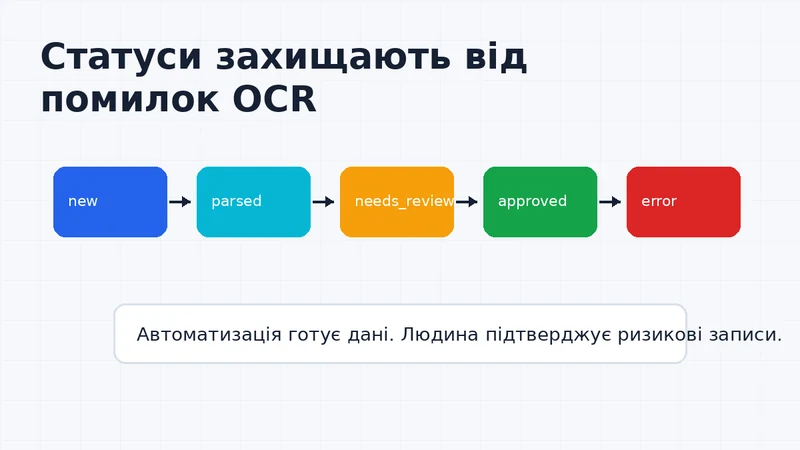
Я б починав із такої моделі:
new- файл знайдено, але ще не оброблено;parsed- дані витягнуті й базово валідні;needs_review- є ризик помилки, потрібна перевірка;approved- людина підтвердила документ;error- файл не вдалося прочитати або обробити.
Ця модель проста, але вона дисциплінує процес. Менеджер або бухгалтер бачить не просто список рахунків, а чергу роботи: що готове, що треба перевірити, що впало.
Запис у Google Sheets
Після валідації можна записувати рядок у таблицю. Для Apps Script це може виглядати так:
function appendInvoiceRow(invoice) {
const sheet = SpreadsheetApp.getActive().getSheetByName("Invoices");
sheet.appendRow([
invoice.date,
invoice.vendor,
invoice.invoice_number,
invoice.amount,
invoice.currency,
invoice.category,
invoice.status,
invoice.source_file_url,
JSON.stringify(invoice.errors || []),
new Date()
]);
}Для Node.js логіка така сама, тільки запис іде через Google Sheets API. Якщо у вас уже є окремі мікросервіси замість no-code сценаріїв, підхід добре поєднується з архітектурою зі статті про мікросервіси на Node.js для Google Workspace.
Як виглядає таблиця контролю
Фінальна таблиця має бути зручною не для розробника, а для людини, яка реально перевіряє документи.
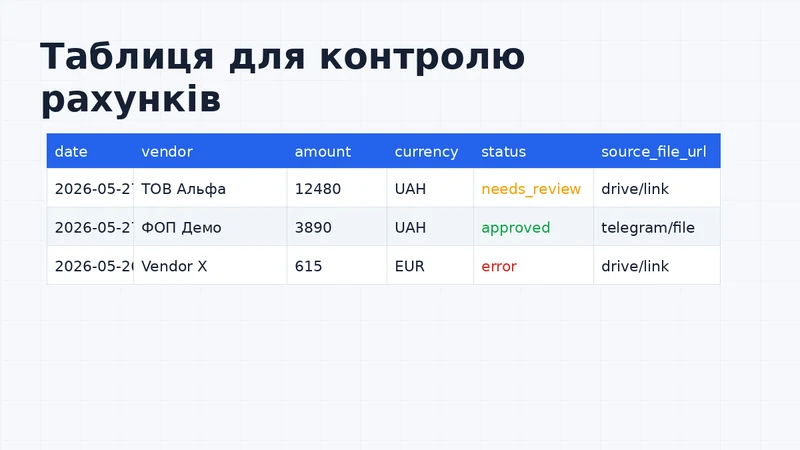
Мінімально корисний вигляд:
- у першому блоці - дата, контрагент, номер, сума, валюта;
- поруч - статус і помилки валідації;
- окремо - посилання на файл;
- далі - хто перевірив і коли.
Якщо документ має статус needs_review, людина відкриває файл за посиланням, виправляє поля й змінює статус на approved. Так автоматизація не забирає контроль, а прибирає найгіршу частину ручної роботи.
Як я прибрав ручне перенесення сум із PDF
У моїх робочих сценаріях найболючішим місцем були не самі рахунки, а повторювані дрібні перевірки. Файл відкрили, суму знайшли, дату переписали, контрагента скоротили, посилання на джерело забули. Потім через кілька тижнів треба зрозуміти, звідки взялася цифра в таблиці.
Я почав не з повної автоматизації, а з напівавтоматичного рядка: система витягувала суму, дату, валюту й назву контрагента, але всі невпевнені документи отримували статус needs_review. У результаті людина перевіряла тільки проблемні місця, а не переносила кожне поле з нуля.
Найбільший ефект був не в "економії 30 секунд на одному рахунку", а в тому, що з'явився контрольний слід. Для кожного рядка було видно файл-джерело, статус і причину перевірки. Це зменшило кількість уточнень і прибрало типову ситуацію "я не пам'ятаю, звідки ця сума".
Де межа такого рішення
Google Sheets добре підходить для першої версії, коли важливо швидко зібрати процес і побачити, де виникають помилки. Але якщо документів багато, є складні маршрути погодження, інтеграція з бухгалтерською системою або кілька юридичних осіб, таблиця має стати лише інтерфейсом перевірки, а не єдиною базою.
Тоді варто додати:
- чергу обробки документів;
- окреме сховище файлів;
- журнал дій;
- ролі доступу;
- повторні спроби для помилок OCR/API;
- інтеграцію з CRM або бухгалтерською системою.
Але починати все одно краще з простого. Одна папка, одна таблиця, один статусний процес і кілька чітких правил дадуть більше користі, ніж складна система без контролю.
Що зробити першим
Якщо у вас уже є хоча б 20-30 рахунків на місяць, перший крок дуже конкретний:
- Створіть таблицю з полями
date,vendor,amount,currency,status,sourcefileurl. - Зберіть 10 реальних рахунків у одну папку.
- Проженіть їх через OCR/LLM extraction.
- Подивіться, які поля система читає стабільно, а які потребують ручної перевірки.
- Тільки після цього автоматизуйте регулярний запис.
Автоматизація рахунків працює найкраще тоді, коли вона не маскує ризики. ШІ може швидко підготувати дані, але бізнесу потрібен не красивий JSON, а надійний процес: зрозуміле джерело, статус, перевірка й контроль у таблиці.
Останні статті

Автоматизація погодження документів у Google Drive: статуси, версії та журнал рішень
Файли final , final new і final v7_approved не показують погоджений документ. Автоматизація погодження документів керує станами, версіями й рішеннями. Для workflow доста…

Тестування AI-автоматизацій: як перевіряти prompts і не ламати результат після оновлення
Зміна в prompt може покращити JSON і зламати зміст. Модель повертає category , але губить примітку клієнта. Тому тестування AI автоматизацій має перевіряти формат і бізн…

Автоматизація комерційних пропозицій: як зібрати Google Docs, PDF і Gmail в один процес
У комерційній пропозиції більша частина роботи повторюється: підставити компанію, контакт, послуги, ціну, строк дії та менеджера. Тому автоматизація комерційних пропозиц…
Google Apps Script security: токени, права доступу і безпечні webhook-автоматизації
Google Apps Script security часто згадують тільки після того, як автоматизація вже працює. Таблиця приймає заявки, Web App отримує webhook-и, Telegram-бот відправляє пов…
OpenAI API cost control: як рахувати токени, ставити ліміти і не отримати несподіваний рахунок
OpenAI API cost control - це не страх перед LLM, а нормальна фінансова гігієна автоматизації. Якщо модель допомагає обробляти заявки, писати summary, класифікувати зверн…
Надійність автоматизації бізнес-процесів: черги, повтори і idempotency без великої інфраструктури
Надійність автоматизації бізнес-процесів починається не з Kubernetes, RabbitMQ або складної cloud-архітектури. У малому бізнесі вона часто починається з простішого питан…