Надійність автоматизації бізнес-процесів: черги, повтори і idempotency без великої інфраструктури
Надійність автоматизації бізнес-процесів починається не з Kubernetes, RabbitMQ або складної cloud-архітектури. У малому бізнесі вона часто починається з простішого питання: що станеться із заявкою, якщо Telegram тимчасово не прийняв повідомлення, Google Apps Script уперся в ліміт або CRM API відповів помилкою?
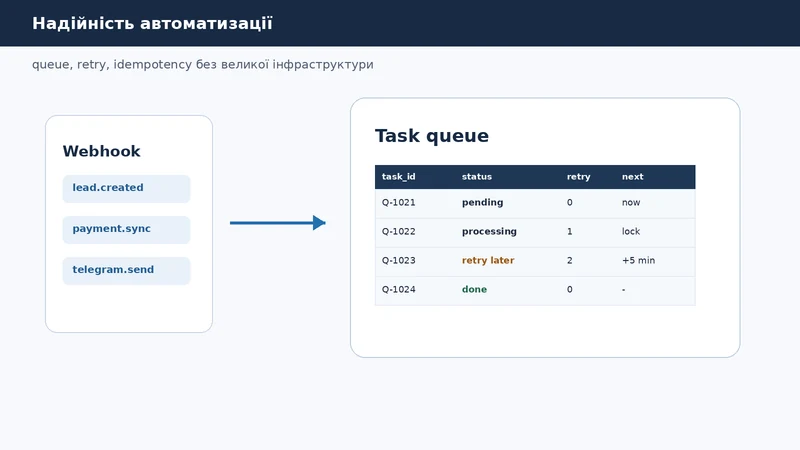
Скрипт, який один раз успішно обробив 10 рядків, ще не є надійною автоматизацією. На реальному обсязі з'являються таймаути, дублікати, частково записані дані, повторні webhook-и і ситуації, коли "просто запустити ще раз" створює ще більше хаосу. Тому між сирим webhook-ом і дією в бізнес-системі потрібен маленький шар дисципліни: queue, retry, idempotency і audit log. Поруч із цим варто мати моніторинг помилок скриптів у Telegram, інакше команда дізнається про збій занадто пізно.
Чому простий скрипт падає на реальних обсягах
На тесті все виглядає акуратно: форма створила заявку, скрипт записав рядок у Google Sheets, потім відправив повідомлення менеджеру в Telegram. Але production поводиться інакше. Клієнти можуть відправити форму кілька разів. Telegram може повернути 429 Too Many Requests. Зовнішній API може не відповідати 20 секунд. Apps Script може завершитися по таймауту саме посередині процесу.
Найгірший варіант - коли скрипт не зберігає стан. Він або "все зробив", або "впав". Бізнес не бачить, яка саме задача втрачена, чи можна її повторити, і чи не створить повтор дубль.
Типові симптоми ненадійної автоматизації:
- заявка є в одній системі, але її немає в іншій;
- менеджер отримав два однакові повідомлення;
- повторний запуск створив другий рядок;
- помилка API загубилася в логах;
- незрозуміло, що вже виконано, а що треба повторити;
- немає межі між тимчасовою помилкою і справжнім
failed.
Надійність тут не означає "ніколи не падати". Вона означає: якщо щось впало, задача не зникла, повтор не створив дубль, а людина бачить стан процесу.
Що таке черга задач
Черга задач - це місце, де автоматизація зберігає роботу до виконання. Для першої версії це може бути не окрема система, а звичайна таблиця Queue у Google Sheets або окремий аркуш у робочій таблиці.
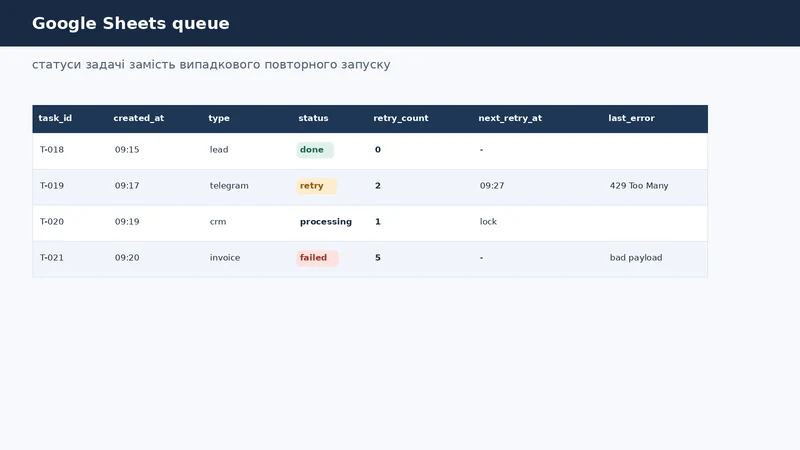
Мінімальна структура:
| Поле | Навіщо потрібно |
|---|---|
task_id | стабільний ID задачі |
created_at | коли задача потрапила в чергу |
type | тип задачі: lead, telegram, crm_sync |
payload_json | вхідні дані |
status | pending, processing, done, failed |
retry_count | скільки разів уже пробували |
nextretryat | коли можна повторити |
last_error | остання помилка |
idempotency_key | ключ для захисту від дубля |
У такій моделі webhook не намагається зробити все одразу. Він спочатку створює задачу в queue. Окремий processor бере pending-задачі і виконує їх невеликими порціями.
function enqueueTask(payload) {
const sheet = SpreadsheetApp.getActive().getSheetByName("Queue");
const taskId = `task_${Date.now()}_${Math.random().toString(36).slice(2, 8)}`;
const idempotencyKey = buildIdempotencyKey(payload);
if (findTaskByIdempotencyKey(idempotencyKey)) {
return { ok: true, duplicate: true, idempotencyKey };
}
sheet.appendRow([
taskId,
new Date().toISOString(),
payload.type || "lead",
JSON.stringify(payload),
"pending",
0,
"",
"",
idempotencyKey
]);
return { ok: true, taskId, idempotencyKey };
}Це вже краще за прямий запис у всі системи з webhook-а. Якщо processor впаде, задача залишиться в таблиці зі статусом pending або processing, а не розчиниться в повітрі.
Таблиця статусів у Google Sheets
Статуси мають бути простими. Якщо команда не розуміє різницю між ними, черга перетвориться на ще один хаос.
Базові статуси:
pending- задача чекає виконання;processing- задача взята в роботу;done- задача успішно виконана;retry- була тимчасова помилка, буде повтор;failed- повтори вичерпано або дані неправильні;skipped- задача не потрібна, наприклад це дубль.
Різниця між retry і failed принципова. retry означає: система ще може сама виправитися. failed означає: автоматизація зупинила задачу і потрібна людина або зміна даних.
function markTask(row, patch) {
const sheet = SpreadsheetApp.getActive().getSheetByName("Queue");
const headers = sheet.getRange(1, 1, 1, sheet.getLastColumn()).getValues()[0];
for (const [key, value] of Object.entries(patch)) {
const col = headers.indexOf(key) + 1;
if (col <= 0) continue;
sheet.getRange(row, col).setValue(value);
}
}Такий helper не робить систему складною, але прибирає ручні помилки: статус, лічильник і помилка оновлюються в правильних колонках.
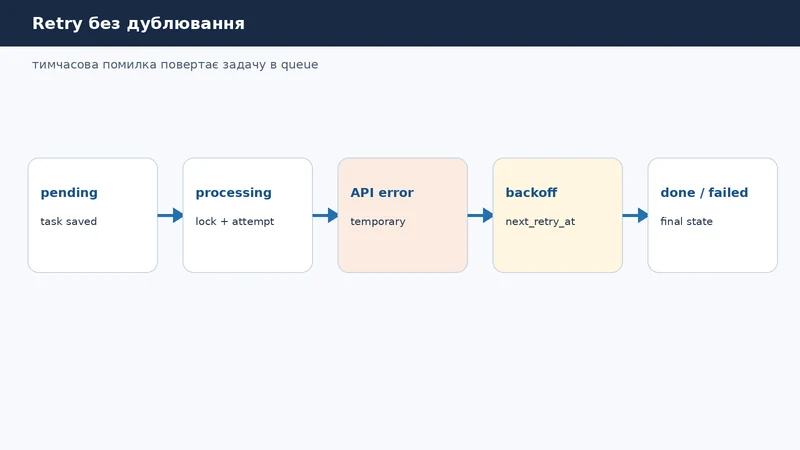
Retry без дублювання
Retry потрібен тільки для тимчасових помилок: timeout, 429, 503, нестабільний API, короткий network error. Якщо payload неправильний або немає обов'язкового поля, повтори не допоможуть. Таку задачу треба одразу переводити в failed.
function shouldRetry(error) {
const message = String(error && error.message || error);
return (
message.includes("429") ||
message.includes("timeout") ||
message.includes("503") ||
message.includes("ECONNRESET")
);
}
function nextRetryAt(retryCount) {
const minutes = Math.min(30, Math.pow(2, retryCount));
return new Date(Date.now() + minutes * 60 * 1000).toISOString();
}Backoff захищає систему від повторного удару по API. Якщо сервіс повернув 429, не треба запускати задачу щосекунди. Краще зробити паузу: 2 хвилини, 4, 8, 16, але з верхньою межею.
processNextTasks()
Processor має брати не всі задачі одразу, а невелику партію. Для Apps Script це особливо важливо, бо є ліміти часу виконання. Перед production треба звірити сценарій з офіційними Apps Script quotas, а якщо таблиця вже не витримує обсяг, порівняти просту queue з Cloud Tasks або Pub/Sub.
function processNextTasks() {
const sheet = SpreadsheetApp.getActive().getSheetByName("Queue");
const values = sheet.getDataRange().getValues();
const headers = values[0];
const statusCol = headers.indexOf("status");
const retryCol = headers.indexOf("retry_count");
const nextRetryCol = headers.indexOf("next_retry_at");
const payloadCol = headers.indexOf("payload_json");
const now = new Date();
let processed = 0;
for (let i = 1; i < values.length && processed < 10; i++) {
const row = values[i];
const status = row[statusCol];
const nextRetry = row[nextRetryCol] ? new Date(row[nextRetryCol]) : null;
if (!["pending", "retry"].includes(status)) continue;
if (nextRetry && nextRetry > now) continue;
const sheetRow = i + 1;
markTask(sheetRow, { status: "processing", last_error: "" });
try {
const payload = JSON.parse(row[payloadCol]);
handleTask(payload);
markTask(sheetRow, { status: "done", last_error: "" });
} catch (error) {
const retryCount = Number(row[retryCol] || 0) + 1;
if (retryCount <= 5 && shouldRetry(error)) {
markTask(sheetRow, {
status: "retry",
retry_count: retryCount,
next_retry_at: nextRetryAt(retryCount),
last_error: String(error.message || error).slice(0, 500)
});
} else {
markTask(sheetRow, {
status: "failed",
retry_count: retryCount,
last_error: String(error.message || error).slice(0, 500)
});
}
}
processed++;
}
}У цій схемі важлива не тільки логіка повторів. Важливо, що кожна помилка залишає слід у таблиці. Якщо задача впала п'ять разів, це видно без пошуку в технічних логах.
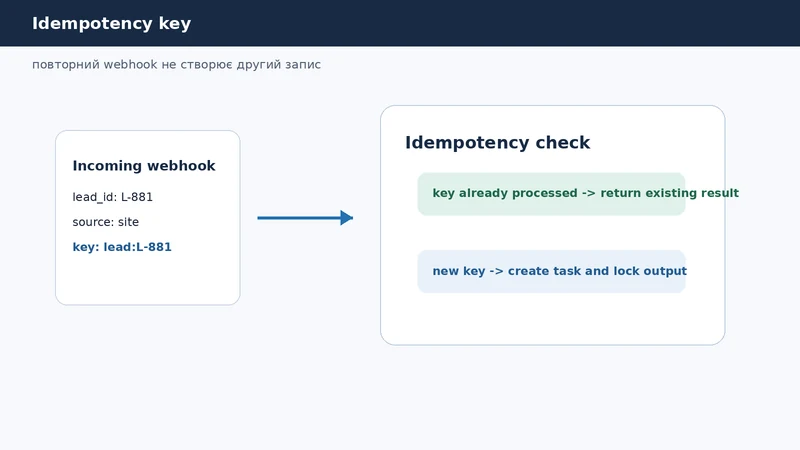
Idempotency key для заявок
Idempotency означає: повторний запуск тієї самої операції не змінює результат вдруге. Для заявок це критично. Один і той самий webhook може прийти повторно через retry на стороні форми або через ручний повтор запиту.
function buildIdempotencyKey(payload) {
if (payload.lead_id) return `lead:${payload.lead_id}`;
if (payload.order_id) return `order:${payload.order_id}`;
return `raw:${Utilities.base64EncodeWebSafe(JSON.stringify(payload)).slice(0, 64)}`;
}
function findTaskByIdempotencyKey(key) {
const sheet = SpreadsheetApp.getActive().getSheetByName("Queue");
const values = sheet.getDataRange().getValues();
const headers = values[0];
const keyCol = headers.indexOf("idempotency_key");
return values.slice(1).find((row) => row[keyCol] === key);
}Якщо ключ уже є, система не створює другу задачу. Вона може повернути існуючий результат або просто сказати: "ця подія вже прийнята". Це особливо корисно для форм, платежів, CRM-sync і Telegram notification layer.
Audit log: видно, що сталося
Черга показує поточний стан, але для розбору інцидентів потрібен audit log. Він не обов'язково має бути складним. Достатньо окремого аркуша QueueLog, куди записуються ключові події.

function writeAuditLog(event) {
const sheet = SpreadsheetApp.getActive().getSheetByName("QueueLog");
sheet.appendRow([
new Date().toISOString(),
event.task_id,
event.type,
event.status,
event.message,
event.retry_count || 0
]);
}Лог має відповідати на прості питання: коли задача створена, коли взята в роботу, що зламалося, скільки було повторів і хто або що її зупинив. Без цього автоматизація стає чорною скринькою.
Як проста черга не дала втратити заявки під час збою API
В одному з робочих сценаріїв форма на сайті передавала заявки в таблицю, CRM і Telegram. На малих обсягах прямий webhook працював нормально. Але коли зовнішній CRM API почав періодично відповідати timeout-ом, частина заявок перестала доходити до CRM. У таблиці вони були, у Telegram іноді були, а в CRM - не завжди.
Рішенням не стала велика інфраструктура. Ми додали queue-аркуш. Webhook тільки приймав заявку і створював задачу з idempotencykey. Processor окремо пробував відправити її в CRM і Telegram. Якщо CRM не відповідала, задача отримувала статус retry, retrycount збільшувався, а nextretryat відкладав повтор. Такий підхід добре поєднується з CRM автоматизацією і дедуплікацією лідів, бо однакова подія не має створювати кілька клієнтських історій.
Найцінніше було не те, що всі задачі "магічно виконалися". Найцінніше - жодна заявка не зникла. Команда бачила, які задачі очікують, які повторюються, які вже виконані, а які потребують ручної перевірки.
Коли таблиці вже мало
Google Sheets queue підходить для старту, невеликих обсягів і прозорого контролю. Але це не вічна архітектура.
Таблиця починає бути вузьким місцем, якщо:
- задачі йдуть тисячами на годину;
- потрібна паралельна обробка багатьма worker-ами;
- важлива низька затримка в секундах;
- потрібні складні dead letter queues;
- кілька систем одночасно пишуть у queue;
- помилки треба маршрутизувати по різних командах.
У цей момент можна переходити до BullMQ, Cloud Tasks, Pub/Sub, SQS або іншої черги. Але якщо команда ще не навчилася працювати зі статусами, retry і idempotency у простій таблиці, складна черга не вирішить проблему процесу.
Практичний підсумок
Надійність автоматизації бізнес-процесів - це не один великий інструмент, а набір простих правил. Задача має зберігатися до виконання. Тимчасова помилка має повторюватися з backoff. Повторний webhook не має створювати дубль. Кожен збій має залишати зрозумілий слід.
Почніть з маленької queue-таблиці: taskid, payloadjson, status, retrycount, nextretryat, lasterror, idempotency_key. Це вже різко зменшує втрати заявок і хаос при повторних запусках. Коли таблиця стане вузьким місцем, ви будете краще розуміти, яку саме production-чергу треба впроваджувати і які правила вона має підтримувати.
Останні статті

Автоматизація погодження документів у Google Drive: статуси, версії та журнал рішень
Файли final , final new і final v7_approved не показують погоджений документ. Автоматизація погодження документів керує станами, версіями й рішеннями. Для workflow доста…

Тестування AI-автоматизацій: як перевіряти prompts і не ламати результат після оновлення
Зміна в prompt може покращити JSON і зламати зміст. Модель повертає category , але губить примітку клієнта. Тому тестування AI автоматизацій має перевіряти формат і бізн…

Автоматизація комерційних пропозицій: як зібрати Google Docs, PDF і Gmail в один процес
У комерційній пропозиції більша частина роботи повторюється: підставити компанію, контакт, послуги, ціну, строк дії та менеджера. Тому автоматизація комерційних пропозиц…
Google Apps Script security: токени, права доступу і безпечні webhook-автоматизації
Google Apps Script security часто згадують тільки після того, як автоматизація вже працює. Таблиця приймає заявки, Web App отримує webhook-и, Telegram-бот відправляє пов…
OpenAI API cost control: як рахувати токени, ставити ліміти і не отримати несподіваний рахунок
OpenAI API cost control - це не страх перед LLM, а нормальна фінансова гігієна автоматизації. Якщо модель допомагає обробляти заявки, писати summary, класифікувати зверн…
RAG для бізнесу: як зробити внутрішній чат-бот по регламентах, FAQ і Google Docs
RAG для бізнесу потрібен не для того, щоб зробити ще одного "розумного чат-бота". Його нормальна задача простіша: дати співробітнику відповідь на основі внутрі…