OpenAI API cost control: як рахувати токени, ставити ліміти і не отримати несподіваний рахунок
OpenAI API cost control - це не страх перед LLM, а нормальна фінансова гігієна автоматизації. Якщо модель допомагає обробляти заявки, писати summary, класифікувати звернення або готувати контент, її витрати мають бути такими ж видимими, як витрати на рекламу чи хостинг.
Ризик зазвичай не в одному дорогому запиті. Ризик у сценарії, який через помилку фільтра обробив не 100 рядків, а 10 000. Або в prompt, куди щоразу передають повну історію клієнта замість короткого контексту. Тому будь-яка LLM-автоматизація має мати usage tracking, денний ліміт і stop condition.
Чому витрати на LLM треба логувати
Якщо ви не пишете usage log, ви бачите витрати тільки постфактум у billing. Для бізнес-процесу це запізно. Потрібно бачити, яка задача, джерело і модель створили витрату.
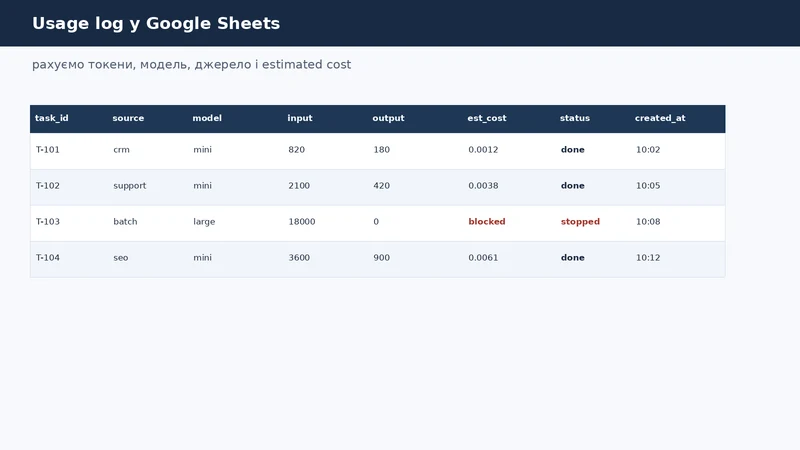
Мінімальні поля:
| Поле | Навіщо |
|---|---|
task_id | зв'язати витрату з конкретною дією |
source | CRM, support, batch, SEO, import |
model | яка модель використана |
prompt_tokens | скільки токенів пішло на input |
completion_tokens | скільки токенів повернула модель |
estimated_cost | попередня оцінка вартості |
status | done, blocked, failed |
created_at | коли стався виклик |
error | помилка або причина зупинки |
function logOpenAiUsage(usage) {
const sheet = SpreadsheetApp.getActive().getSheetByName("OpenAI_Usage");
sheet.appendRow([
usage.task_id,
usage.source,
usage.model,
usage.prompt_tokens,
usage.completion_tokens,
usage.estimated_cost,
usage.status,
new Date().toISOString(),
usage.error || ""
]);
}У Responses API та інших викликах OpenAI API треба читати usage з відповіді, якщо він доступний, і не покладатися тільки на приблизну оцінку до запиту. Але guard перед запуском все одно потрібен. Базову реалізацію варто звіряти з офіційною документацією OpenAI text generation, а актуальні тарифи - зі сторінкою OpenAI API pricing.
Денний бюджет і stop condition
Budget guard має працювати до виклику моделі. Якщо денний ліміт уже вичерпано, задача не повинна запускатися "ще один раз".

function checkDailyBudget(source) {
const today = new Date().toISOString().slice(0, 10);
const usage = readUsageRows(today, source);
const spent = usage.reduce((sum, row) => sum + Number(row.estimated_cost || 0), 0);
const dailyLimit = Number(getSetting(`daily_limit_${source}`) || 5);
return {
ok: spent < dailyLimit,
spent,
dailyLimit
};
}
function assertBudgetBeforeRun(task) {
const budget = checkDailyBudget(task.source);
if (!budget.ok) {
logOpenAiUsage({
task_id: task.id,
source: task.source,
model: task.model,
prompt_tokens: 0,
completion_tokens: 0,
estimated_cost: 0,
status: "blocked",
error: `Daily limit reached: ${budget.spent} / ${budget.dailyLimit}`
});
throw new Error("OpenAI daily budget reached");
}
}Ліміти краще задавати окремо: один для support summary, інший для batch-контенту, третій для тестів. Інакше маленький runaway batch може з'їсти бюджет процесу, який потрібен щодня. Наприклад, AI помічник для продажів і RAG для внутрішніх документів мають різну частоту запитів, різний контекст і різні бюджетні guardrails.
Як зменшити довгі prompts
Prompt optimization починається не з "взяти дешевшу модель", а з input hygiene. Не передавайте моделі весь CRM-рядок, якщо їй потрібні тільки 8 полів. Не передавайте повний чат, якщо достатньо останніх 5 реплік і короткого summary.
function prepareInput(raw) {
return {
client_name: raw.client_name,
source: raw.source,
message: String(raw.message || "").slice(0, 2000),
last_notes: (raw.notes || []).slice(-5),
previous_summary: raw.previous_summary || ""
};
}Для великих документів краще робити попереднє summary або retrieval, а не кидати все в один prompt. Для відповідей, де потрібен короткий результат, ставте output limit. Так ви контролюєте не тільки input, а й completion_tokens.
Приклад розрахунку 1000 операцій
Не варто записувати конкретну ціну моделі як вічну істину. Перед production потрібно звірити актуальні ціни на офіційній сторінці OpenAI Pricing: https://openai.com/api/pricing/.
Формула проста:
total_cost =
(input_tokens / 1_000_000 * input_price_per_1m) +
(output_tokens / 1_000_000 * output_price_per_1m)Для 1000 операцій структура розрахунку така:
function estimateBatchCost({ operations, inputTokens, outputTokens, inputPrice, outputPrice }) {
const totalInput = operations * inputTokens;
const totalOutput = operations * outputTokens;
return (
totalInput / 1_000_000 * inputPrice +
totalOutput / 1_000_000 * outputPrice
);
}Якщо одна операція має 2000 input tokens і 400 output tokens, то для 1000 операцій треба рахувати 2 000 000 input tokens і 400 000 output tokens. Ці числа вже можна множити на актуальні ціни конкретної моделі.
Як денний ліміт захищає від runaway automation
У робочому сценарії batch-скрипт мав обробити 120 нових рядків. Через помилку фільтра він почав брати весь архів. Без guard це виглядало б як нормальна робота: модель відповідає, таблиця заповнюється, витрати ростуть.
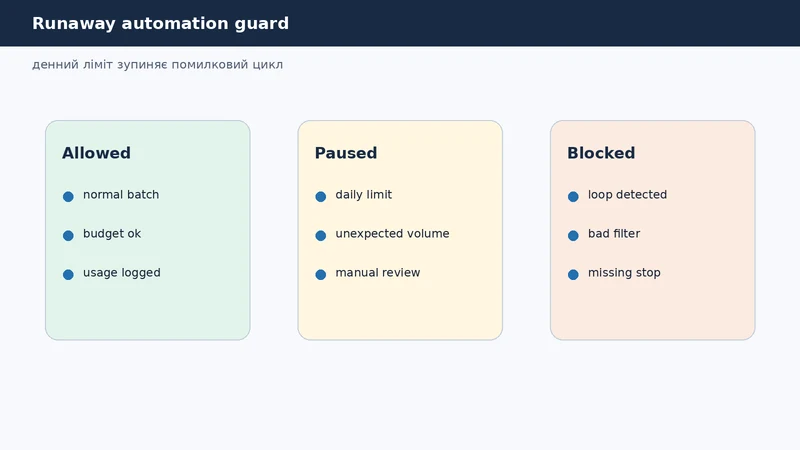
Денний ліміт зупинив процес після перших підозрілих витрат. У usage log було видно source=batch, різкий ріст task_id і однаковий тип задачі. Це дозволило виправити фільтр до того, як автоматизація витратила місячний бюджет. Для таких сценаріїв корисно додати ті самі принципи, що й у надійності автоматизації бізнес-процесів: queue, audit log і stop condition.
Практичний підсумок
OpenAI API cost control складається з кількох простих правил: логувати usage, рахувати tokens, мати daily_limit, перевіряти бюджет до запуску задачі, обрізати зайвий input і зупиняти runaway loops. Це не ускладнює автоматизацію. Навпаки, робить її передбачуваною.
Почніть з аркуша OpenAI_Usage, функції logOpenAiUsage(), guard-а checkDailyBudget() і формули розрахунку для 1000 операцій. Коли витрати видно по задачах і джерелах, LLM перестає бути "чорним ящиком" і стає звичайним керованим інструментом бізнес-автоматизації.
Останні статті

Автоматизація погодження документів у Google Drive: статуси, версії та журнал рішень
Файли final , final new і final v7_approved не показують погоджений документ. Автоматизація погодження документів керує станами, версіями й рішеннями. Для workflow доста…

Тестування AI-автоматизацій: як перевіряти prompts і не ламати результат після оновлення
Зміна в prompt може покращити JSON і зламати зміст. Модель повертає category , але губить примітку клієнта. Тому тестування AI автоматизацій має перевіряти формат і бізн…

Автоматизація комерційних пропозицій: як зібрати Google Docs, PDF і Gmail в один процес
У комерційній пропозиції більша частина роботи повторюється: підставити компанію, контакт, послуги, ціну, строк дії та менеджера. Тому автоматизація комерційних пропозиц…
Google Apps Script security: токени, права доступу і безпечні webhook-автоматизації
Google Apps Script security часто згадують тільки після того, як автоматизація вже працює. Таблиця приймає заявки, Web App отримує webhook-и, Telegram-бот відправляє пов…
Надійність автоматизації бізнес-процесів: черги, повтори і idempotency без великої інфраструктури
Надійність автоматизації бізнес-процесів починається не з Kubernetes, RabbitMQ або складної cloud-архітектури. У малому бізнесі вона часто починається з простішого питан…
RAG для бізнесу: як зробити внутрішній чат-бот по регламентах, FAQ і Google Docs
RAG для бізнесу потрібен не для того, щоб зробити ще одного "розумного чат-бота". Його нормальна задача простіша: дати співробітнику відповідь на основі внутрі…