Побудова власного AI-Lead Gen комбайна: Puppeteer + OpenAI API
База лідів без аналізу — це просто шум. Якщо ви зібрали домени, email-адреси чи назви компаній, але не розумієте, хто з них реально схожий на вашого клієнта, далі починається спам під виглядом outreach. У цьому і проблема “брудних” баз: парсинг сам по собі ще не дає корисного сигналу.

Робочий підхід інший: ви не просто збираєте сторінки, а проганяєте їх через власний пайплайн аналізу. Headless-браузер рендерить сайт, витягує контент із DOM-дерева, далі LLM повертає структуровані дані: коротке резюме бізнесу, скоринг від 0 до 10 і причину, чому цей лід варто або не варто брати в роботу. Такий мікросервіс для бізнесу дорожчий у розробці на старті, але значно гнучкіший за готові lead-gen платформи.
Чому тут працює саме зв’язка Puppeteer + OpenAI API

Puppeteer закриває технічну частину, де звичайний HTTP-парсер часто ламається: SPA, відкладене рендерення, складні селектори, прихований текст у вкладках, lazy-loaded блоки. Якщо ваш ICP живе у B2B-сегменті, то значна частина сайтів буде саме такою.
OpenAI API закриває другий шар — інтерпретацію. Вам не потрібно вручну вигадувати 20 regex-правил, щоб зрозуміти, чи це агенція, SaaS, локальний сервісний бізнес чи виробник. Ви віддаєте в модель очищений текст, просите повернути JSON і працюєте вже зі структурованими даними, а не з сирим HTML.
Логіка роботи пайплайна
Базова схема виглядає так:
- переходимо на сайт
- чекаємо завершення рендеру
- дістаємо текст із
header,main,section,footer,h1-h3 - чистимо сміття: повтори, зайві пробіли, cookie-банери, навігацію
- відправляємо короткий, але жорсткий промпт у модель
- отримуємо JSON зі скорингом і summary
- складаємо результат у таблицю, БД або чергу
На цьому етапі вже можна будувати фільтр “брати в outreach / не брати”. А якщо зверху додати enrichment, сегментацію та черги, то це вже не просто парсер, а повноцінний AI-Lead Gen контур.
Базовий ініт Puppeteer
Почнемо з мінімального ESM-варіанта без зайвих абстракцій:
import puppeteer from "puppeteer";
export async function fetchPageText(url) {
const browser = await puppeteer.launch({
headless: "new",
args: ["--no-sandbox", "--disable-setuid-sandbox"]
});
const page = await browser.newPage();
await page.setViewport({ width: 1440, height: 900 });
await page.goto(url, {
waitUntil: "networkidle2",
timeout: 45000
});
const raw = await page.evaluate(() => {
const nodes = document.querySelectorAll(
"header, main, section, article, footer, h1, h2, h3, p, li"
);
return Array.from(nodes)
.map(node => node.innerText || "")
.join("
");
});
await browser.close();
return raw;
}Це не “бойова” версія, але її достатньо, щоб отримати текст для першого скорингу. Далі ви вже додаєте проксі, ротацію user-agent, повторні спроби та чорні списки доменів.
Очищення тексту перед токенізацією
Якщо відправляти в модель все підряд, ви просто спалюєте токени на навігації, cookie-блоках і дублях. Тому нормалізація — не косметика, а частина економіки рішення.
export function cleanExtractedText(input = "") {
return input
.replace(/\s+/g, " ")
.replace(/cookie|privacy|accept all|terms/gi, " ")
.replace(/home|about|services|contact/gi, " ")
.replace(/[^\S
]+/g, " ")
.trim()
.slice(0, 8000);
}У реальному проєкті цей шар краще робити трохи розумнішим: окремо чистити header/footer, окремо викидати технічні повтори й залишати тільки фрагменти, де справді є “About”, “Services”, “Who we help”, “Industries”, “Case studies”.
Запит до OpenAI з JSON-відповіддю
Тут важливо не просити “проаналізуй красиво”. Потрібен жорсткий контракт: тільки JSON, тільки потрібні поля, тільки короткий summary. Це зменшує варіативність і спрощує подальшу обробку даних на Node.js.
export async function scoreLead(text) {
const response = await fetch("https://api.openai.com/v1/chat/completions", {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${process.env.OPENAI_API_KEY}`
},
body: JSON.stringify({
model: "gpt-4o-mini",
response_format: { type: "json_object" },
messages: [
{
role: "system",
content: "You analyze company websites and return strict JSON only."
},
{
role: "user",
content:
`Проаналізуй сайт і поверни JSON з полями:
score (0-10),
summary,
business_type,
services,
target_audience,
why_fit.
Текст сайту: ${text}`
}
],
temperature: 0.2
})
});
const json = await response.json();
return JSON.parse(json.choices[0].message.content);
}На виході ви вже маєте не просто текст, а структуровані дані, які можна сортувати, фільтрувати й подавати в CRM, Google Sheets або власний ендпоінт.
Де тут економіка, а не просто “цікава інженерія”
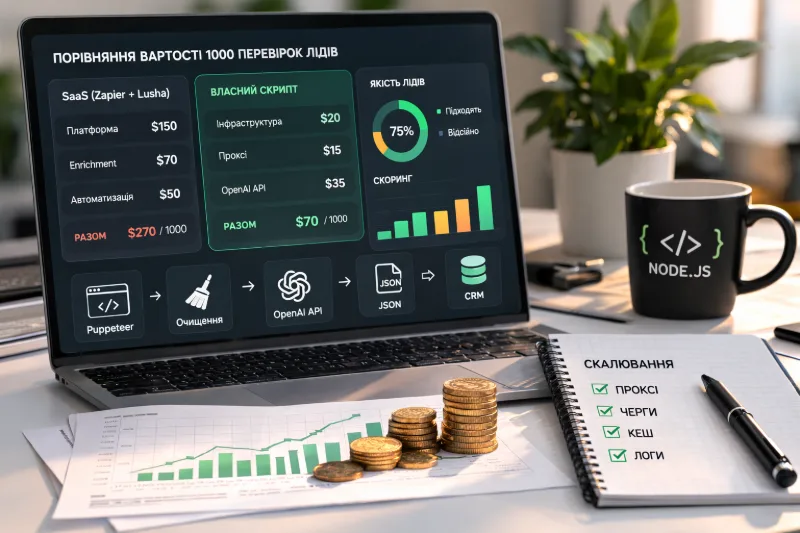
У SaaS-інструментів витрати зазвичай ростуть по трьох осях: обсяг контактів, кількість автоматизацій і доступ до enrichment-функцій. У власному сценарії модель інша: ви платите за інфраструктуру запуску, проксі за потреби та токени OpenAI. Якщо відсікти погані ліди ще до ручного outreach, то вартість однієї корисної перевірки зазвичай виглядає краще, ніж у зв’язці “парсер + enrichment + Zapier”.
Тут важлива не магічна цифра “1000 перевірок”, а контроль. Ви самі вирішуєте, який обсяг тексту брати, як жорстко чистити дані, які поля повертати в JSON і який поріг скорингу вважати робочим. Для команди, яка регулярно робить outbound, це вже не разова автоматизація, а частина операційного контуру.
Як масштабувати без переписування з нуля
Щоб не впертися в межу після першої тисячі доменів, одразу закладайте просту архітектуру:
- черга задач на обхід доменів
- окремий воркер для Puppeteer
- окремий воркер для LLM-аналізу
- кеш по домену, щоб не аналізувати один сайт двічі
- проксі для масового обходу
- логування HTML-помилок, timeouts і порожніх сторінок
Якщо робити це послідовно, то з простого скрипта виростає нормальний internal tool. А якщо вам потрібен не тільки AI lead gen, а й базова інфраструктура для інбаунду, лендінгів або B2B-вітрини під цей процес, можна паралельно замовити сайт і вже на нього накладати власні скрипти збору, скорингу та маршрутизації лідів.
Суть проста: не збирайте все, що рухається. Збирайте те, що можна технічно валідувати, змістовно оцінити й автоматично передати в наступний крок пайплайна.
Останні статті

Автоматизація погодження документів у Google Drive: статуси, версії та журнал рішень
Файли final , final new і final v7_approved не показують погоджений документ. Автоматизація погодження документів керує станами, версіями й рішеннями. Для workflow доста…

Тестування AI-автоматизацій: як перевіряти prompts і не ламати результат після оновлення
Зміна в prompt може покращити JSON і зламати зміст. Модель повертає category , але губить примітку клієнта. Тому тестування AI автоматизацій має перевіряти формат і бізн…

Автоматизація комерційних пропозицій: як зібрати Google Docs, PDF і Gmail в один процес
У комерційній пропозиції більша частина роботи повторюється: підставити компанію, контакт, послуги, ціну, строк дії та менеджера. Тому автоматизація комерційних пропозиц…
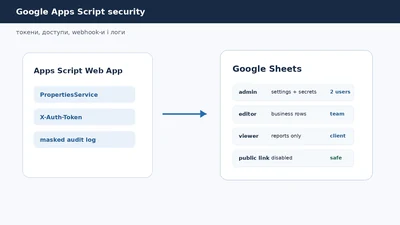
Google Apps Script security: токени, права доступу і безпечні webhook-автоматизації
Google Apps Script security часто згадують тільки після того, як автоматизація вже працює. Таблиця приймає заявки, Web App отримує webhook-и, Telegram-бот відправляє пов…
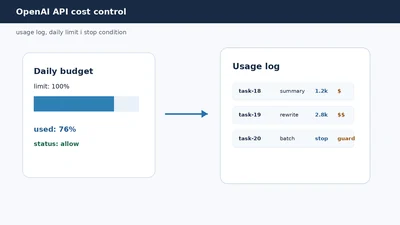
OpenAI API cost control: як рахувати токени, ставити ліміти і не отримати несподіваний рахунок
OpenAI API cost control - це не страх перед LLM, а нормальна фінансова гігієна автоматизації. Якщо модель допомагає обробляти заявки, писати summary, класифікувати зверн…
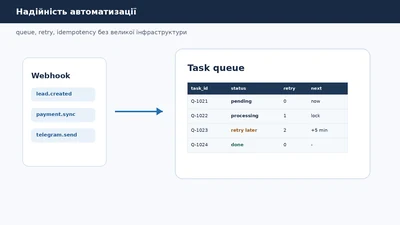
Надійність автоматизації бізнес-процесів: черги, повтори і idempotency без великої інфраструктури
Надійність автоматизації бізнес-процесів починається не з Kubernetes, RabbitMQ або складної cloud-архітектури. У малому бізнесі вона часто починається з простішого питан…