RAG для бізнесу: як зробити внутрішній чат-бот по регламентах, FAQ і Google Docs
RAG для бізнесу потрібен не для того, щоб зробити ще одного "розумного чат-бота". Його нормальна задача простіша: дати співробітнику відповідь на основі внутрішніх документів компанії, а не загальних знань моделі. Якщо правила продажів лежать у Google Docs, FAQ підтримки - у старій таблиці, а onboarding - у кількох посиланнях у чаті, люди все одно будуть перепитувати одне й те саме.
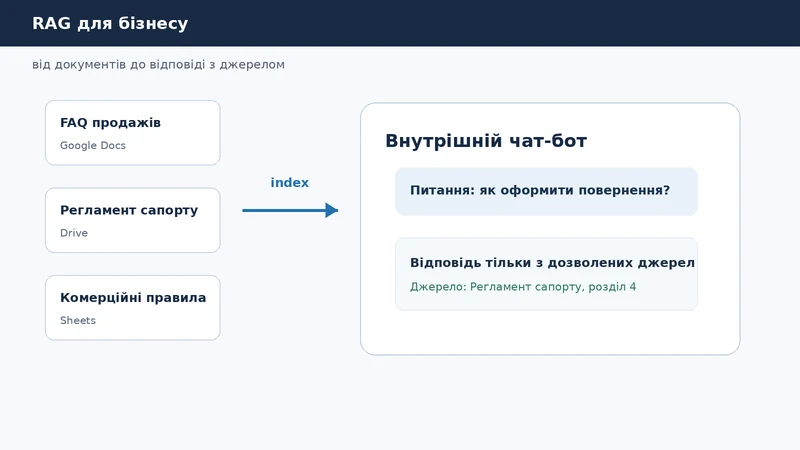
Звичайний ChatGPT може добре пояснювати загальні речі, але він не знає ваших регламентів, актуальних цінових правил, внутрішніх винятків і доступів. RAG закриває саме цю прогалину: система спочатку знаходить релевантні фрагменти у дозволених документах, а вже потім просить модель сформувати коротку відповідь із посиланням на джерело.
Чому звичайний ChatGPT не знає ваші регламенти
У бізнесі проблема рідко в тому, що співробітник не може сформулювати питання. Проблема в тому, що правильна відповідь живе не в одному місці. Новий менеджер питає, як погодити нестандартну знижку. Оператор підтримки шукає, що робити з поверненням. Керівник хоче зрозуміти, який шаблон договору актуальний. Усі ці відповіді можуть бути в документах, але шлях до них займає час.
Якщо просто скопіювати питання в ChatGPT, модель відповість із загальної картини світу. Вона може звучати впевнено, але не бачити вашого Google Drive, історії оновлень і прав доступу. Для внутрішніх процесів це небезпечно: красива відповідь без джерела може бути гіршою за чесне "я не знаю".
RAG змінює порядок роботи. Модель не вигадує знання з повітря. Вона отримує знайдений контекст: уривки з регламенту, FAQ або інструкції. Якщо контексту немає, система повинна відмовитися відповідати або попросити уточнення. Для технічної частини варто окремо розібрати embeddings у документації OpenAI embeddings, а бізнес-обмеження витрат - у статті про OpenAI API cost control.
Як працює RAG простими словами
RAG - це retrieval augmented generation, тобто генерація з попереднім пошуком контексту. Практично це виглядає як конвеєр: документи розбиваються на невеликі фрагменти, для кожного фрагмента створюється embedding, а питання користувача шукає найближчі за змістом chunks у векторному індексі.
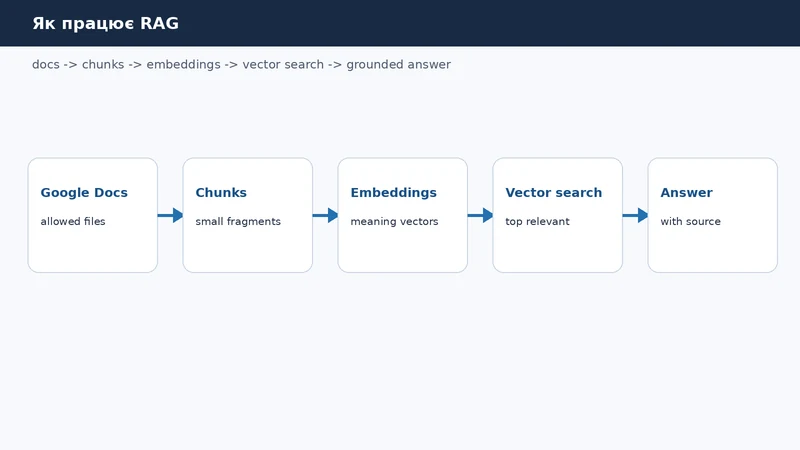
Типовий flow:
- Indexer читає дозволені Google Docs, Sheets або Markdown-файли.
- Кожен документ розбивається на chunks по 500-1000 слів або менше, якщо це інструкція.
- Для chunk створюється embedding.
- Chunk зберігається у vector search разом із metadata: джерело, власник, ролі доступу, дата оновлення.
- Користувач ставить питання в Telegram, Slack або веб-інтерфейсі.
- Система шукає релевантні chunks тільки серед тих, які користувачу дозволено бачити.
- Модель отримує питання, знайдений контекст і правило не вигадувати відповідь без джерела.
Саме metadata робить внутрішній чат-бот бізнесовим інструментом, а не просто красивою обгорткою над LLM.
Архітектура внутрішнього чат-бота
Для першої робочої версії не треба індексувати весь Google Drive. Краще взяти 20-50 документів, які справді часто використовуються: FAQ продажів, регламент підтримки, onboarding, правила знижок, інструкції по заявках і типові шаблони відповідей. Якщо джерелом є Google Docs, інтеграцію краще будувати поверх офіційного Google Docs API, а не через ручне копіювання тексту.
const DocumentChunk = {
chunk_id: "sales-faq-018-03",
document_id: "sales-faq-018",
title: "FAQ продажів",
text: "Якщо знижка більша за 12%, потрібне погодження...",
source_url: "https://docs.google.com/document/d/...",
owner: "sales",
allowed_roles: ["sales", "admin"],
updated_at: "2026-05-28",
checksum: "sha256:..."
};Архітектура може бути такою:
- Google Drive або Google Docs як джерело документів;
- indexer, який за розкладом читає дозволені файли;
- chunking layer, який не ріже таблиці й списки випадково посередині;
- embeddings service;
- vector search або hosted file search;
- query endpoint на Node.js;
- Telegram або Slack bot як простий інтерфейс для команди.
Важливо не змішувати два процеси. Індексація документів відбувається окремо. Відповідь користувачу відбувається окремо. Так легше контролювати оновлення, кеш, помилки й права доступу.
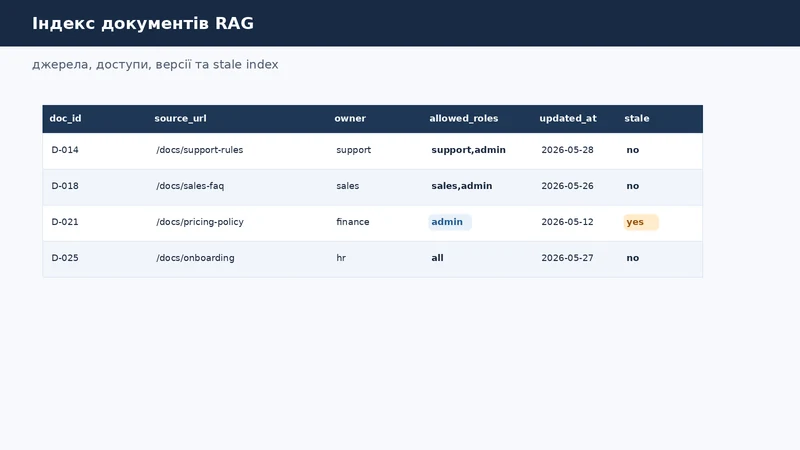
Структура індексу документів
Мінімальний індекс має зберігати не тільки текст. Без джерела, власника й ролей доступу RAG швидко стає ризиком для компанії.
async function indexDocuments(documents) {
for (const doc of documents) {
if (!doc.indexable) continue;
const rawText = await readGoogleDoc(doc.source_url);
const chunks = splitIntoChunks(rawText, {
maxTokens: 700,
keepHeadings: true
});
for (const chunk of chunks) {
await vectorStore.upsert({
id: `${doc.id}:${chunk.index}`,
text: chunk.text,
metadata: {
document_id: doc.id,
title: doc.title,
source_url: doc.source_url,
owner: doc.owner,
allowed_roles: doc.allowed_roles,
updated_at: doc.updated_at
}
});
}
}
}У production-версії варто зберігати checksum документа або timestamp останнього редагування. Якщо документ не змінився, його не треба переіндексувати. Якщо змінився, старі chunks треба оновити, а не створити другий дубль інструкції.
Пошук релевантних chunks
Пошук має враховувати два фільтри: зміст питання і доступ користувача. Якщо менеджер продажів питає про знижку, система може шукати у sales FAQ. Якщо він питає про фінансовий регламент, але не має доступу, цей документ не повинен потрапити в prompt.
async function searchRelevantChunks(question, user) {
const results = await vectorStore.search({
query: question,
topK: 6,
filter: {
allowed_roles: { $contains: user.role },
stale: false
}
});
return results.map((item) => ({
text: item.text,
title: item.metadata.title,
source_url: item.metadata.source_url,
updated_at: item.metadata.updated_at
}));
}Не треба сліпо брати 20 фрагментів. Занадто багато контексту розмиває відповідь і збільшує витрати. На старті краще повертати 3-6 chunks і логувати, які джерела реально допомогли відповісти.
Prompt, який забороняє вигадувати
Для внутрішньої бази знань prompt має бути жорсткішим, ніж для звичайного асистента. Він не повинен "допомагати будь-якою ціною".
function buildRagPrompt(question, chunks) {
return `
Ти внутрішній AI-помічник компанії.
Відповідай тільки на основі контексту нижче.
Якщо контекст не містить відповіді, напиши: "У доступних документах немає достатньої інформації".
Не вигадуй правила, ціни, винятки або процедури.
Додай коротке посилання на джерело після відповіді.
Питання:
${question}
Контекст:
${chunks.map((chunk, index) => `
[${index + 1}] ${chunk.title}
Джерело: ${chunk.source_url}
Оновлено: ${chunk.updated_at}
Текст: ${chunk.text}
`).join("
")}
`;
}Це правило захищає від найгіршого сценарію: бот відповів упевнено, але не мав жодного дозволеного джерела. У внутрішніх процесах краще чесна відмова, ніж вигаданий регламент.
Права доступу і приватні документи
Блок про права доступу не можна залишати "на потім". Якщо індексатор бачить усі документи, а чат-бот відповідає всім співробітникам однаково, ви фактично створили неконтрольований канал витоку внутрішніх правил.

Для кожного chunk варто зберігати:
source_url- звідки взято фрагмент;owner- хто відповідає за документ;allowed_roles- хто може бачити відповідь на основі цього фрагмента;updated_at- коли джерело востаннє змінювалося;stale- чи можна використовувати цей chunk для відповіді;confidenceабо score пошуку, якщо його дає ваш retrieval layer.
Якщо користувач не має доступу до джерела, бот не повинен показувати ні текст документа, ні переказ цього тексту. Це важливо: переказ приватного документа теж є витоком.
Як оновлювати індекс
Індекс старіє тихо. Документ у Google Docs змінили, а vector store все ще містить старий chunk. На перший погляд бот працює. Насправді він може давати відповідь за регламентом, який уже скасували.
Мінімальна схема оновлення:
- раз на годину або день перевіряти
modifiedTimeдокументів; - переіндексувати тільки змінені файли;
- видаляти chunks для документів, які більше не дозволені;
- позначати старі правила як
stale, якщо власник ще не підтвердив нову версію; - логувати, з яких джерел бот відповідав користувачам.
async function refreshIndex() {
const docs = await listApprovedDriveDocs();
for (const doc of docs) {
const previous = await indexState.get(doc.id);
if (previous?.modifiedTime === doc.modifiedTime) continue;
await vectorStore.deleteByMetadata({ document_id: doc.id });
await indexDocuments([doc]);
await indexState.set(doc.id, {
modifiedTime: doc.modifiedTime,
indexed_at: new Date().toISOString()
});
}
}Якщо документ важливий для продажів або фінансів, корисно додати ручне підтвердження власником: "ця версія дозволена для відповідей бота". Це зменшує ризик, що чернетка регламенту випадково стане джерелом правди.
Telegram AI bot як інтерфейс
Для першого запуску Telegram або Slack часто зручніші за окремий веб-кабінет. Люди вже там працюють, тому не треба привчати команду до ще одного інструмента.

async function answerInternalQuestion({ user, question }) {
const chunks = await searchRelevantChunks(question, user);
if (!chunks.length) {
return "У доступних документах немає достатньої інформації.";
}
const response = await llm.generate({
input: buildRagPrompt(question, chunks)
});
return response.text;
}У повідомленні варто показувати не тільки відповідь, а й джерело. Наприклад: "Джерело: FAQ продажів, розділ 3, оновлено 2026-05-28". Це допомагає співробітнику перевірити контекст і швидко перейти до повного документа.
Як внутрішній пошук зменшує повторні питання
В одному з робочих сценаріїв повторні питання виникали не через лінощі команди, а через розкидані документи. Новий менеджер питав старшого, як оформити виняток у комерційній пропозиції. Оператор підтримки шукав, хто погоджує повернення. Керівник витрачав час на відповіді, які вже були описані в регламентах.
Після запуску вузького RAG-пошуку команда почала ставити ці питання боту. Важливо, що бот не "знав усе". Він відповідав тільки по кількох дозволених документах: sales FAQ, support rules і onboarding. Якщо відповіді не було, він так і писав. Це виявилося корисніше за універсального асистента, який намагається допомогти навіть без контексту.
Ефект був операційний: менше повторних питань у чатах, швидший onboarding і більше дисципліни в документах. Коли люди бачать, що бот бере відповідь із конкретного джерела, вони починають краще підтримувати це джерело в актуальному стані.
З чого почати без великої платформи
Починайте не з "проіндексувати весь Drive", а з маленької бази знань:
- Виберіть 20-50 документів, які справді часто потрібні.
- Призначте власника кожного документа.
- Очистіть заголовки, дублікати й застарілі правила.
- Додайте metadata: ролі, source URL, дату оновлення.
- Зробіть простий Telegram або Slack endpoint.
- Логуйте питання, на які бот не зміг відповісти.
- Раз на тиждень оновлюйте документи за цими провалами.
RAG для бізнесу корисний там, де є стабільні документи і повторні питання. Якщо процес змінюється щодня, спочатку наведіть порядок у джерелах. Якщо джерела вже є, але люди їх не знаходять, внутрішній чат-бот може швидко зняти частину рутини. Для безпечного запуску поруч варто закласти правила з Google Apps Script security, особливо якщо бот читає внутрішні документи.
Головне - не обіцяти, що бот "знає все". Правильна обіцянка інша: бот швидко шукає у дозволених документах, коротко відповідає, показує джерело і чесно мовчить там, де джерела немає. Для бізнесу це набагато цінніше за ще одну універсальну AI-іграшку.
Останні статті

Автоматизація погодження документів у Google Drive: статуси, версії та журнал рішень
Файли final , final new і final v7_approved не показують погоджений документ. Автоматизація погодження документів керує станами, версіями й рішеннями. Для workflow доста…

Тестування AI-автоматизацій: як перевіряти prompts і не ламати результат після оновлення
Зміна в prompt може покращити JSON і зламати зміст. Модель повертає category , але губить примітку клієнта. Тому тестування AI автоматизацій має перевіряти формат і бізн…

Автоматизація комерційних пропозицій: як зібрати Google Docs, PDF і Gmail в один процес
У комерційній пропозиції більша частина роботи повторюється: підставити компанію, контакт, послуги, ціну, строк дії та менеджера. Тому автоматизація комерційних пропозиц…
Google Apps Script security: токени, права доступу і безпечні webhook-автоматизації
Google Apps Script security часто згадують тільки після того, як автоматизація вже працює. Таблиця приймає заявки, Web App отримує webhook-и, Telegram-бот відправляє пов…
OpenAI API cost control: як рахувати токени, ставити ліміти і не отримати несподіваний рахунок
OpenAI API cost control - це не страх перед LLM, а нормальна фінансова гігієна автоматизації. Якщо модель допомагає обробляти заявки, писати summary, класифікувати зверн…
Надійність автоматизації бізнес-процесів: черги, повтори і idempotency без великої інфраструктури
Надійність автоматизації бізнес-процесів починається не з Kubernetes, RabbitMQ або складної cloud-архітектури. У малому бізнесі вона часто починається з простішого питан…